Teknologi for utvikling av en norsk barnestemme
Skrevet av: Morten Tollefsen, Dyre Meen og Miriam Begnum
Sist oppdatert: 14.12.2010
Innhold
3. Barnestemmer og de store, kommersielle aktørene
3.1 Endring av parametre i eksisterende synteser
8. Bruk av talesynteser i hjelpemidler for barn
1. Innledning
Det er gjort store fremskritt i utviklingen av talesyntese. Et viktig utviklingstrekk er at "stemmene" likner mer på mennesker. Talesyntese brukes i GPS-systemer, skjermlesere for synshemmede, opplesing av tekst for dyslektikere, MP3-spillere, mobiltelefoner, automatiserte telefonisystemer og mye annet.
Bruksområdet som fokuseres i forprosjektet "Barnestemme" er talesyntese brukt som kommunikasjonshjelpemiddel for barn. Det har vært lite fokus på utvikling av barnestemmer. Barn som benytter talesyntese for å kommunisere må bruke en syntetisk voksenstemme, noe som ikke er ønskelig.
Barnestemme-prosjektet er støttet av IT Funk (Norges forskningsråd). Følgende skal vurderes i prosjektet:
- Tekniske løsninger som kan brukes for å lage en norsk barnestemme.
- Identifisere viktige FoU-utfordringer.
- Legge grunnlaget for et hovedprosjekt hvis dette er realistisk.
I dette notatet gjennomgås ulik teknologi og noen vurderinger mht. hvor realistisk det er å implementere en norsk barnestemme. I neste avsnitt beskrives teknologi for talesyntese som bakgrunn for resten av notatet.
2. Talesynteseteknologi
Talesyntese er produksjon av tale fra tekst. Ofte benyttes forkortelsen TTS: eng. text-to-speach. Talesynteser har ulike egenskaper og bruksområder. Ofte vil forståelighet og hvor naturlig talen høres ut være viktige kriterier for å bedømme kvalitet. I noen sammenhenger vil imidlertid responstid og opplesing av nøyaktig den teksten som leses opp (f.eks. tydelig uttale av skrivefeil) være viktige egenskaper. Synshemmede foretrekker eksempelvis ofte eldre talesynteser nettopp fordi disse leser nøyaktig og forståelig (til og med på andre språk enn det syntesen er laget for). På den annen side finnes det en rekke applikasjoner der en mest mulig naturtro (menneskeliknende) syntese er å foretrekke: telefonisystemer rettet mot almennheten, lydbøker produsert med syntetisk tale, talende nettsider etc. Demonstrasjon av norske stemmer finnes på [9].
Beskrivelse av talesyntese inklusive en historisk gjennomgang finnes på [8].
En TTS motor består av en front-end og en back-end. Front-end'en har to primæroppgaver. Først konvertere tekst med forkortelser, symboler osv. til fullt utskrevne ord (tekstnormalisering). Deretter legges det på fonetiske transkripsjoner til hvert ord, og teksten merkes og deles opp i prosodiske enheter (fraser, setninger osv). Fonetisk transkripsjon og prosodisk informasjon utgjør den symbolske, lingvistiske representasjonen som leveres fra front-end'en. Back-end'en (talesynthesizeren) konverterer så denne representasjonen til lyd.
De to primære teknologiene for å generere syntetisk tale er konkatenativ syntese og formant-syntese.
2.1 Konkatenativ syntese
Konkatenativ syntese genererer tale ved å "lime sammen" lydsegmenter. Denne teknologien gir normalt de mest naturlige stemmene, men små variasjoner i naturlig tale og hvordan lydsegmentene settes sammen fører ofte til hørbare feil. Det er tre hovedtyper av konkatenativ syntese:
Datadrevet bølgeformsyntese: En stor database med lydopptak brukes for å generere tale som passer til det som skal sies. Ulike teknikker benyttes for å plukke ut hvilke lyder som skal benyttes. Lydene kan være fonemer, men også hele ord, fraser eller setninger.
- Difonsyntese: I motsetning til datadrevet skjøtesyntese brukes en liten lyd-database. Basen inneholder alle kombinasjoner av to fonemer (difoner). Kvaliteten på syntesen er som regel mer robot-aktig enn synteser som benytter datadrevet skjøtesyntese. Ulike teknikker for digital lydbehandling benyttes imidlertid for å forbedre difonsyntesen, og kvaliteten er normalt bedre enn for formant-synteser.
- Synteser for spesifikke applikasjoner: Dersom ordforrådet er begrenset kan i prinsippet alle ord/fraser leses inn, og kvaliteten kan bli veldig god. Teknologien for å generere meldinger er svært enkel, og kommersielle applikasjoner har vært på markedet lenge. Et eksempel er DAISY-spillere med innleste meldinger. Meldingene brukes f.eks. til å lese opp klokkeslett og dato, fortelle brukeren hvor lenge det er igjen av boka osv.
2.2 Formantsyntese
Formantsyntese krever ikke lydopptak. Kun regler benyttes for å gjøre tekst om til lyd. Stemmene som genereres blir robot-aktige, men kan være forståelige når du venner deg til talemåten. Formantsynteser krever lite minne og prossessorkraft. Stemmene kan være forståelige også når de snakker med høy hastighet.
2.3 Andre synteseteknologier
- Artikulasjonssyntese (eng. Articulatory synthesis): Syntese som genereres ved hjelp av teknikker som simulerer det menneskelige taleorganet.
- HMM-basert syntese: Frekvensspekter (taleorganet), fundamental frekvens (talekilde) og varighet (prosodi) av tale beregnes samtidig ved hjelp av skjulte Markov modeller (jfr. Kap. 5).
- Sinusbølge syntese: En teknikk for talesyntese der formanter erstattes med rene plystretoner.
3. Barnestemmer og de store, kommersielle aktørene
Kommersielle aktører som tilbyr norske stemmer er Acapela, Loquendo, Nuance og Lingit.
Acapela ser ikke noe kommersielt potensiale i barnestemmer generelt, og absolutt ikke for små språk som norsk. Heller ikke Loquendo har utviklet spesifikke barnestemmer. Både Acapela og Loquendo fåreslo å benytte voksenstemmer og endre parametre på disse (se neste avsnitt) som teknikk for å simulere barnestemmer.
Nuance selger ikke synteser til sluttbruker. Disse syntesene bundles med ulike produkter (GPSer, Jaws for Windows osv). I Barnestemme-prosjektet har vi derfor ikke tatt kontakt med Nuance.
Lingit var langt mer imøtekommende mht. å finne gode løsninger for barnestemmer da prosjektet kontaktet firmaet. Lingit's teknologi og en foreløpig ide til fremstillingen av barnestemmer beskrives i kapittel 5.
3.1 Endring av parametre i eksisterende synteser
Acapela har vært innvolvert i forbindelse med behovet for barnestemmer [3]. Det har imidlertid ikke vært snakk om "ekte barn". Utgangspunktet har vært voksenstemmer der ulike parametre (f.eks. tonehøyde) er endret. Eksempler på dette er stemmene Kenny og Nelly [4]. På et møte med Acapela fikk vi vite at dette ble brukbart mottatt i engelskspråklige land, men at endring av parametre på voksenstemmer ikke hadde fått noen god mottakelse i Norden. Om dette skyldes aktuelle nordiske stemmer, selve språkene eller kvalitetskrav til hjelpemidler vites ikke.
Vi har eksperimentert litt med norske Acapela-stemmer uten å få til stemmer som likner barn. Acapelas datadrevne skjøtesynteser (Kari og Olav) lar seg dessuten i liten grad modifisere.
Loquendo foreslår også å bruke voksenstemmer som utgangspunkt og deretter endre parametre [5]. Vi har forsøkt dette med den norske stemmen Vilde uten gode resultater.
4. Filibuster
"Den norske syntetiske stemmen Brage er en av tre stemmer til tekst-til-tale (TTS) systemet Filibuster. Filibuster er utviklet av det svenske Talboks- og punktskriftsbiblioteket (TPB). Bokmålsstemmen Brage er utviklet av Norsk lyd- og blindeskriftbibliotek (NLB) i samarbeid med TPB. Uttaleleksikonet bygger på data fra den norske Språkbanken. Talesyntesen Brage har vært i bruk siden september 2009. Filibuster er en serverbasert datadrevet bølgeformsyntese. Systemet er basert på enhetsseleksjon, en av flere konkatenative teknologier. Filibuster genererer automatisk tale gjennom seleksjon og konkatenering av lydsegmenter. Disse lydsegmentene hentes fra en omfattende lyddatabase med innspilte setninger." [1]
Utviklingen av Brage baseres på et omfattende datamateriale. Uttaleleksikonet består av 780000 bokmålsord fra Språkbanken, 16000 ord fra det svenske systemet og 50000 egennavn fra HLT Resource Collection (og det svenske systemet). Transkribering er tilpasset norsk SAMPA [2]. Stemmedatabasen til Brage består av 15604 innspilte setninger. Tekstkorpuset er representativt for NLBs produksjoner. Filibustersystemet har en tekstprosessor som kan detektere språk, dvs. bytte mellom hovedspråket og engelsk.
Filibuster er altså laget spesielt for produksjon av lydbøker, og stemmen Brage benyttes av NLB for egne produksjoner. Det er også utviklet en nettbasert applikasjon for lydproduksjon som kan benyttes av ulike læresteder. Applikasjonen heter PipeOnline og denne er utviklet av DAISY-konsortiet.
Koden i Filibuster er åpen, men om den er fritt tilgjengelig og om noe av arbeidet med Brage kan benyttes i forhold til utvikling av en barnestemme er uklart. Det å spille inn tilsvarende datamengde som for Brage vil opplagt by på problemer med små barn. Som nevnt er også Filibuster server-basert, og hvor omfattende det vil være å flytte teknologien til klientutstyr vites ikke. Vår foreløpige vurdering er at denne teknologien ikke lar seg anvende for utvikling av barnestemmer.
5. HMM-baserte synteser
Talesyntese basert på skjulte Markov-modeller (såkalt HMM-basert talesyntese) har fått mye oppmerksomhet i forskningsmiljøer de siste årene. Denne synteseteknologien benytter i stor grad velkjente strategier fra talegjenkjenning. En HMM-basert stemme trenger, i likhet med for eksempel konkatenativ syntese, en større samling lydopptak av en taler. Denne brukes til å trene opp matematiske modeller for talerens akustiske egenskaper og intonasjon (lydvarigheter og grunntonefrekvens). Lingit har utviklet to stemmer basert på denne teknologien.
Ved syntetisering av lyd brukes ikke lydopptakene direkte (slik som i konkatenativ syntese). All nødvendig informasjon for å generere lyd er bakt inn i modellen, som kan sees på som en form for komprimert lydbank. Dette medfører fordeler og ulemper når man sammenligner med konkatenativ syntese:
- Modellen har et svært lite fotavtrykk, i størrelsesorden noen få megabyte. Konkatenativ syntese har et fotavtrykk på opptil flere hundre megabyte.
- Modellen har vist seg godt egnet til å generere svært naturlig intonasjon - det vil si at den er i stand til å gjøre en god tilnærming av den faktiske taleren.
- Modellen generaliserer. Det er mulig å generere glatte lydoverganger - det vil si overganger uten sjenerende lydartifakter.
- Synteseteknologien oppnår en jevn og forutsigbar lydkvalitet. Dette er for mange en viktig egenskap til den oppfattede totalkvaliteten. Konkatenativ syntese har på sin side større variasjon i kvaliteten. På sitt beste snakker vi om avspilling av et faktisk lydopptak, noe som kan sies å tilfredstille "perfekt kvalitet", men generelt må man skjøte sammen lyder. Lydskjøting kan føre til svært variabel kvalitet.
- Den veldefinerte matematiske beskrivelsen muliggjør manipulering av talerkarakteristikk. Ved hjelp av matematiske transformasjoner kan man endre for eksempel talerens stemmeleie, humør eller kjønn.
På [10] kan man finne demonstrasjoner av hvordan HMM-baserte syntetiske stemmer kan manipuleres. Denne egenskapen gjør teknologien interessant i forbindelse med barnestemmer. Det store problemet med å lage en barnestemme er at man vanligvis trenger store mengder lydopptak av tildels komplisert tekst. Dette er krevende, selv for voksne erfarne innlesere og antageligvis umulig for et ungt barn. Løsningen i kontekst av HTS-syntese er i stedet å gjøre en mindre mengde barneopptak og bruke dette for å manipulere en eksisterende voksenstemme i retning av barnet. Vår hypotese er at dette vil fungere bedre enn å endre parametre for en eksisterende voksenstemme.
6. Taleboka
Normedia har utviklet Taleboka [6]. Dette er en samling med lydfiler (ca. 100000). Lydfilene inneholder hele ord. Bokstaver, tegn og tall er også lest inn. Ord som ikke er innlest kan staves.
Siden hvert ord i Taleboka er lest inn er kvaliteten svært god. Brukes Taleboka for å lese opp hele setninger hører du imidlertid at det er enkeltord som leses. Setningsrytmen blir med andre ord ikke riktig.
Det er laget et SAPI5-grensesnitt mot taleboka, og dermed kan den benyttes av et bredt utvalg programvare, for eksempel sammen med SymWriter, Programsnekker, og Textpilot.
7. Barns ordforråd
Språkforskere ved Universitetet i Oslo har kartlagt små barns språkutvikling [7] – opp til 36 måneder. Jenter snakker normalt før gutter, og små barn skjønner flere ord enn de klarer å si. De fleste snakker ganske mye før de er to år gamle. De første ordene barnet lærer (i denne rekkefølgen) er: mamma, pappa, hei, nam-nam, brr (billyd), nei, ha det, borte (i forb med lek), bæææ, grrr, voff voff, ja. Denne tidligste språkutviklingsfasen varer opp til ca. 3 år og kalles systeminnlæringsfasen.
Ordforrådet varierer naturligvis mye. Hos 24 måneder gamle barn er antall produktive ord fra 19 til 615 [7, 11]. Mens 50 prosent av jentene kan si 200 ord allerede når de er 20 måneder gamle, kan 50 prosent av guttene bare si halvparten så mange ord på samme alderstrinn. Forskjellene jevner seg gradvis ut, og ved 36 måneders alder har guttene nesten tatt igjen jentenes forsprang. Tabell 1 viser norske barns ordforråd.
Av tabellen ser vi at ordforrådet til tre år gamle barn er fra 600 til 700 ord. Eldre barn har naturligvis et større ordforråd. Etter den første systeminnlæringen kommer en systemstabiliseringsfase (4-6 år), og til sist en tekstutviklingsfase fra 6 års alder [12]. Man regner med at en gjennomsnittlig norsk 4-åring har ca.2000 ord i aktivt språk, pluss ca. 8000 i passivt ordforråd [17]. En 5-åring kan ca.2000 - 3000 ord og mestrer de vanligste ordene i språket vårt [11].
| Alder | Kan si (antall ord) | Kan forstå (antall ord) |
|---|---|---|
| 8 mnd | Ingen | 0-50 |
| 12 mnd | 0-20 | 20-160 |
| 16 mnd | 5-80 | 60-260 |
| 20 mnd | 30-250 | 140-370 |
| 24 mnd | 170-420 | |
| 30 mnd | 450-650 | |
| 36 mnd | 600-700 | |
| 4 år | Ca.2000 | |
| 5 år | ca.2000 - 3000 |
Tabell SEQ Tabell \* ARABIC 1: Norske barns ordforråd
Danske [13, 18] og svenske [14, 15, 16] studier viser liknende resultater. Danske barn bruker noe lenger tid på å knekke språkkoden, men fra 2-års alder er antall begreper i ordforrådet ganske likt for de tre skandinaviske språkene. Tabellen under viser danske og svenske data, til sammenlikning.
| Alder | Dansk ordforråd | Svensk ordforråd |
|---|---|---|
| 2 – 2 ½ | 2-300 | 300 |
| 2 ½ – 3 | 800-1000 | - |
| 3 | - | Nærmer seg 1000 |
| 3 – 4 | 1500 | - |
| 4 – 5 | 1500-2000 | 1500-2000 |
| 5 – 6 | Ca. 2200 | ca.2200 - 2500 |
Tabell SEQ Tabell \* ARABIC 2: Danske og svenske barns ordforråd
Alderen 6-12 kjennetegnes av sterk språklig utvikling, med skolestart og utvikling av lese- og skriveferdigheter. En typisk norsk 6-åring vil ved skolestart ha rundt 10-15 000 ord i sitt ordforråd [11, 17, 19]. Det passive ordforrådet er imidlertid større enn det aktive, og barn i alderen 2-6 år har gjerne ikke et stabilt begrepsinnhold på alle ordene [11]. Til sammenlikning har vi som voksne et ordforråd på mellom 50 000 og 250 000 ord [19].
Barn som trenger syntetisk eller innlest tale for å kommunisere vil sannsynligvis ofte ha et mindre ordforråd, og rent praktisk vil det også være begrensninger mht. å få brukt et omfattende ordforråd på en hensiktsmessig måte for barna. For barn uten språk men med god språkforståelse er utfordringen å finne egnede brukergrensesnitt mot talesystemet dersom dette er omfattende. For barn med nedsatt kognitiv funksjonsevne vil et begrenset ordforråd være aktuelt.
8. Bruk av talesynteser i hjelpemidler for barn
Alternativ Supplerende kommunikasjon (ASK) hjelpemidler kan ha tre typer funksjoner; som uttrykksmiddel, som støttespråk (gjerne ved forsinket språkutvikling, ikke varig behov) eller som språkalternativ (morsmål) [22]. Det eksisterer en rekke ulike grafiske tegnsystemer som kan brukes i ASK hjelpemidler i tillegg til standard skrifttegn, for eksempel Pictogram, BLISS, PCS, WLS og Symbolstix. Disse kan referere til ord, fraser eller setninger. Ofte brukes også fotografier i ASK grensesnitt. Tegnsystemene kan brukes i utskrevne formater (f. eks papir), men kan også være lagt inn som symbolspråk i talemaskiner.
Talemaskiner og programvare for kommunikasjon er ofte basert på hierarkiske valg. Hovedvalg er gjerne plassert i en toppmeny. Hver rute leder til en undermeny, som for eksempel er tilknyttet en spesiell aktivitet. Selv om betjeningsmetodene varierer er dette grensesnittet ganske likt. Kompleksiteten og innholdet i grensesnittet er tilpasset hver enkelt bruker.
Ofte får både gutter og jenter i dag en voksen damestemme som sin stemme. Den kan de få i 3-4 års alder og ha opp til 12-14 år (for gutter, jenter vil beholde damestemmen også etter tenårene).
Abilia (tidligere Falck Igel og Gewa) er et selskap som daglig jobber med levering og tilpasning av kommunikasjonsløsninger til barn med behov for ASK [20, 21]. Abilia mener ASK barn i dag gjerne blir begrenset av omgivelsene, og får tilgang til et for lite ordforråd. De ønsker å gi barna så stor frihet som mulig – dvs at de primært ønsker full syntese.
Per i dag opplever Abilia at barna kommer til dem når de er veldig store, gjerne 6, 8 eller 12 åringer som ikke tidligere har hatt hjelpemidler. De har nå et ”tidlig intensjons” prosjekt for å dokumentere at det er nyttig å starte mye før, for eksempel ved 6-8 mnds alder. For de minste barna viser forskning at innlesing er best. Her er synteser ikke ønskelig. Abilia tror imidlertid at en barnesyntese kan være nyttig helt ned i 2-årsalderen. For den initielle satsingen på utvikling av en norsk barnestemme kan det likevel se ut som dette er aller mest aktuelt for en stemme fra og med ca. 6-8 år.
Abilia bruker i dag den ”voksne” Taleboka, men melder at de tilgjengelige voksne talesyntesene er desidert mest brukt. En full syntese gir ASK barn mer fleksibilitet i frie kommunikasjonssettinger. Dersom en full HMM syntese utvikles, er det ønskelig med mulighet for å redigere uttale av enkeltord ved å justere lydskriften.
Med bakgrunn i barns begrensede ordforråd er Taleboka likevel ikke uaktuell i forhold til utviklingen av norske barnestemmer. Spesielt for små barn kan man tenke seg at det leses inn et begrenset antall ord (f.eks. de 700 typiske ordene treåringer benytter). Dette vil være en realistisk oppgave, og det er ikke vanskelig å utvikle ulike stemmer (spesielt er det behov for en guttestemme og en jentestemme).
Abilia bruker Rolltalk og Programsnekker, og er teknisk klare til å ta i bruk Talebok løsning med barnestemme når/om den blir laget, dersom den utvikles på samme måte som Taleboka i dag. De henter inn lydfilene som en vilkårlig talesyntese. Dette vil foregå på samme måte med en Talebok-løsning eller en HMM syntese.
Det er ikke nødvendig med skriveferdigheter for å bruke fri tale, da man kan bygge setninger fra symboler. Under er et eksempel fra SymWriter [6], der setningen ”Levende tale lyder flott!” er skrevet med symboler.
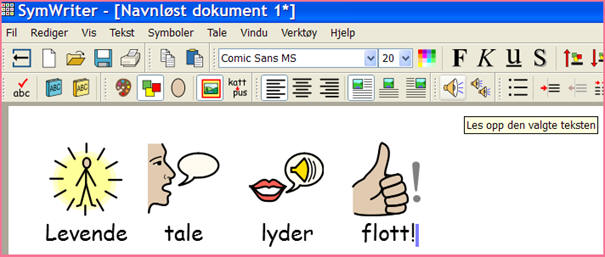
Figur SEQ Figur \* ARABIC 1 - SymWriter: setning fra symboler
Rable/bable muligheter med barnesyntese før skriveferdigheter er på plass vil i tillegg antakelig også være positivt for språkutvikling.
9. Konklusjon
Acapela og Loquendo mener at det ikke er kommersielt interessant å utvikle ekte barnestemmer. Begge disse aktørene foreslår å benytte voksenstemmer og endre på parametre (tonehøyde, klang etc). Tester gjort med endring av parametre på eksisterende, norske voksenstemmer viser at denne fremgangsmåten ikke kan benyttes for å simulere en troverdig barnestemme. Nuance som kun bundler talesynteser er ikke kontaktet i dette prosjektet.
TPB og NLB har utviklet en serverbasert, norsk talesyntese. Teknologien som benyttes heter Filibuster og skal være basert på åpen kildekode. Om kode og data kan gjenbrukes av andre er uvisst. Vi har ikke fått respons på de henvendelsene som er gjort i denne sammenheng. Det er uansett ikke sannsynlig at det vil være hensiktsmessig å benytte Filibuster for å lage barnestemmer. De to viktigste grunnene er at det kreves omfattende lydopptak og at teknologien er serverbasert. I Barnestemme-prosjektet er det imidlertid ikke gjennomført analyser av hva som kreves for å flytte teknologien til typisk klientutstyr eller om dette i det hele tatt er realistisk.
Taleboka kan være et interessant alternativ for stemmer med begrenset ordforråd (f.eks. små barn). Denne synteseløsningen vil gi svært tydelig og forståelig uttale, men leser kun ord for ord (ikke setninger). Det er laget SAPI-grensesnitt mot boka, og denne kan derfor i prinsippet benyttes av alle aktuelle PC-baserte applikasjoner.
Eldre barn og ungdommer med stor språkforståelse vil sannsynligvis være tjent med en mer tradisjonell talesyntese. For barnestemmer der ordforrådet skal være stort er derfor en HMM-basert syntese et spennende alternativ å gå videre med. Med fokus på frihet og delaktighet, kan man se for seg størst nytte av en syntetisk barnestemme i frie kommunikasjonssettinger, for eksempel i lek. En mer setningsbasert løsning enn Normedias Talebok vil da være hensiktsmessig. Begrensede opptak av barn kan kombineres med modeller for ferdige voksenstemmer i produksjon av en slik syntese.
10. Referanser
1: Den syntetiske stemmen Brage
http://no.wikipedia.org/wiki/Den_syntetiske_stemmen_Brage
2: SAMPA computer readable phonetic alphabet
http://www.phon.ucl.ac.uk/home/sampa/index.html
3: Revolutionising communication, tango! the sound of a child's voice by Acapela.
http://www.acapela-group.com/revolutionising-communication-tango-the-sound-of-a-child-s-voice-by-acapela--150-speech-synthesis.html
4: AssistiveWare - Infovox iVox Mac OS X voices for text to speech
http://www.assistiveware.com/ivoxsamples.php?voice=Nelly_iVox_HQ
5: Loquendo TTS Multimedia Package and Voice Creator Now Available
http://www.loquendo.com/en/news/news_loquendo_multimedia_package.htm
6: Taleboka TTS talesyntese
http://www.normedia.no/taleboka_tts_talesyntese
7: Slik er barnets språkutvikling
http://www.klikk.no/foreldre/dinbaby/utvikling/article508854.ece
8: Speech synthesis
http://en.wikipedia.org/wiki/Text_to_speech#Synthesizer_technologies
9: MediaLT: test av norske talesynteser
http://medialt.no/syntese/
10: Junichi Yamagishi
http://homepages.inf.ed.ac.uk/jyamagis/Demo-html/
11: Oppvekst. Kommunikasjon og samhandling, Bente Vetland Thorkildsen. Kap 3: Språk, identitet og personlighetsutvikling (s.70-115). Gyldendal (2007). ISBN/EAN: 9788205374072
12: Generelt om barns språkutvikling, Høgskolen i Østfold, fra Barns språkutvikling av Anne Høigård
http://www.fag.hiof.no/~bk/F%C3%B8rskolen/Høigårdkap1.ppt
13: Den sproglige udvikling hos det normalthørende barn i alderen 0-5 år, Aalborgskolen 2006, B. H. Klausen, N. Holst-Hansen, T. Søby og P. Solhoft
www.ci-info.dk/documents/00061.pdf
14: Barns språkutveckling, GoBoken
http://www.goboken.se/Artiklar-om-barn/Om-sprak-och-lasning/Barns-sprakutveckling/
15: Barns språkutveckling, Språkfakta
http://www.ling.gu.se/projekt/sprakfrageladan/svenska/sprakfakta/sv-lang-dev.html
16: Barns språkutveckling i förskoleåldern 1-6 år fra Förskoleålderns psykologi av Ulla-Brita Bruun
http://www.buf.kristianstad.se/v_vram/Barns%20spr%C3%A5kutveckling%20i%20f%C3%B6rskole%C3%A5ldern.htm
17: Barns utvikling
http://no.wikipedia.org/wiki/Barns_utvikling
18: Sproglig udvikling,
http://www.happelappeland.dk/html/kompetencer/sproglig_udvikling.htm
19: Det mentale leksikonet, Marianne Lind, Universitet i Oslo LING 1105 (2009)
http://www.uio.no/studier/emner/hf/iln/LING1105/v09/Det%20mentale%20leksikon(1).pdf
20: Alternativ och kompletterande kommunikation, Abilia
http://www.abilia.se/material/index.aspx?cat=257685&id=1269
21: ASK-IT, Abilia
http://www.abilia.no/material/index.aspx?cat=300484&id=19922
22:Funksjonelle hovedgrupper, ASK-loftet
http://www.tks2.no/ask2/malgruppe/hovedgrupper.html
Tips noen om siden